 Als ich Punkt 5.3 zum ersten Mal gesehen habe, hatte ich einen Déjà-vu-Effekt, als würde ich mich wieder auf eine ITIL-Zertifizierung vorbereiten. In diesem Abschnitt geht es um die Implementierung der operativen Kontrolle auf Basis von ITIL und ISO/IEC 20000-1- Standards.
Als ich Punkt 5.3 zum ersten Mal gesehen habe, hatte ich einen Déjà-vu-Effekt, als würde ich mich wieder auf eine ITIL-Zertifizierung vorbereiten. In diesem Abschnitt geht es um die Implementierung der operativen Kontrolle auf Basis von ITIL und ISO/IEC 20000-1- Standards.
ITIL basiert grundsätzlich auf gesundem Menschenverstand und einer logischen Vorgehensweise, so reichen bei manchen Punkten bereits die Namen aus, um deren Inhalt korrekt wiederzugeben.
ITIL (Information Technology Infrastructure Library) ist ein weltweit verbreitetes Framework für IT-Service-Management (ITSM). ITIL beschreibt Best Practices für die Planung, Bereitstellung und den Betrieb von IT-Diensten.
ISO/IEC 20000-1 ist der internationale Standard für IT-Service-Management, welcher auf ITIL-Prinzipien basiert. Der Unterschied: ITIL ist ein Framework mit Empfehlungen (das „Wie“), ISO/IEC 20000-1 hingegen ist ein Standard mit konkreten Anforderungen, zertifiziert zu werden (das „Muss“).
Change Management
Das Change Management ist ein strukturierter und reglementierter Prozess zur Einführung von Änderungen in IT-Infrastrukturen. Ein Change Request ist wahrscheinlich einer der bekanntesten Managementprozesse in der IT-Welt, kaum ein IT-Mitarbeiter kennt ihn nicht.
Besonders in der Cloud ist es notwendig, Änderungen schnell, sicher und nachvollziehbar zu implementieren. Mit Hilfe von CI/CD (Continuous Integration/Continuous Deployment) lässt sich die technische Umsetzung automatisieren. Das Change Management regelt lediglich den Genehmigungsprozess.
Alle unten aufgeführten Schritte können mit einem einzigen Softwareprodukt abgewickelt werden (z. B. ServiceNow, Jira Service Management oder BMC Remedy).
Kernkomponenten des Change-Prozesses
Alle unten aufgeführten Schritte können mit einem einzigen Softwareprodukt abgewickelt werden.
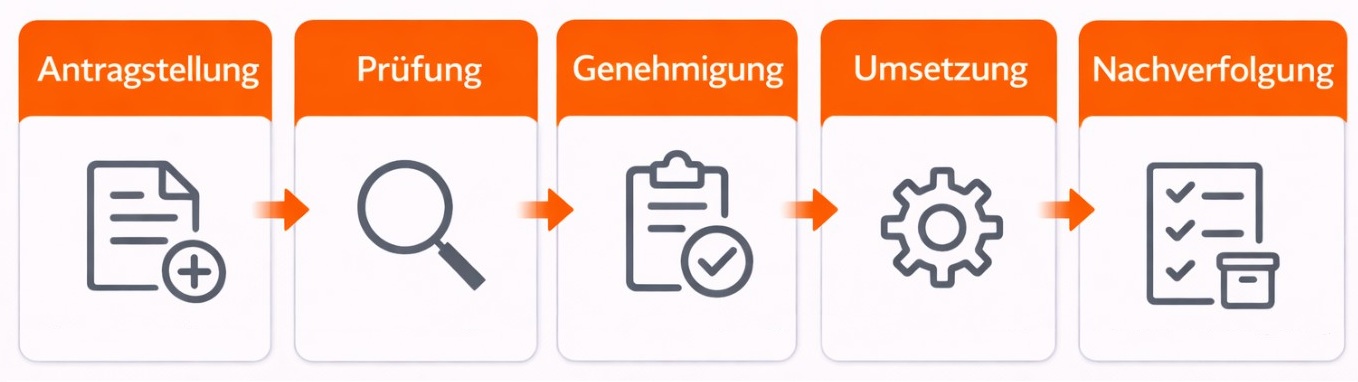
Strukturierte Vorgehensweise. Jede Änderung folgt einem festgelegten Prozess: Antragstellung, Prüfung, Genehmigung, Umsetzung und Nachverfolgung.
Risikobewertung und Impact-Analyse. Die Änderungen werden nach Risikostufen kategorisiert (niedrig, normal, hoch, Notfall). Je höher das Risiko, desto umfangreicher ist das erforderliche Freigabe- und Testverfahren. Vorab müssen potenzielle Auswirkungen auf Systeme, Daten und Benutzer analysiert werden.
Change Advisory Board (CAB): Ein Team aus technischen und organisatorischen Stakeholdern, das Änderungen bewertet das Änderungen bewertet und entweder genehmigt oder ablehnt.
Ticket- und Review-Systeme: Alle Änderungen müssen dokumentiert sein, um die Nachvollziehbarkeit und Auditierung zu ermöglichen.
Rollback-Planung: Falls eine Änderung unerwartete Störungen verursacht, muss ein Rollback-Plan existieren, der eine schnelle Rückkehr zum vorherigen Zustand ermöglicht.
Continuity Management
Die vollständige Bezeichnung dieses Punktes lautet Business Continuity Management (BCM) und bezieht sich darauf, IT-Systeme und Geschäftsprozesse auch bei Störungen unterschiedlicher Art betriebsfähig zu halten. Im ITIL-Kontext ist BCM ein Teilprozess des Service Design. Alle relevanten Inhalte wurden bereits ausführlich in Abschnitt 3.5 behandelt.
Information Security Management
Information Security Management beschäftigt sich mit dem systematischen Schutz von Informationen auf Basis der drei Grundprinzipien Vertraulichkeit, Integrität und Verfügbarkeit (CIA-Triade). Im ITIL-Kontext umfasst es den gesamten Managementrahmen – von Sicherheitsrichtlinien über Risikomanagement bis hin zu Audits.
Die relevanten Inhalte sind im Abschnitt 6.3 „Verständnis des Auditprozesses“ und 6.4. „Auswirkungen der Cloud auf das Risikomanagement“ detailliert beschrieben.
Continual Service Improvement Management
Der Name Continual Service Improvement (CSI) sagt eigentlich schon alles. Bei diesem Punkt geht es darum, dass IT-Systeme nie endgültig fertiggestellt sind, sondern sich immer weiter verbessern lassen, um sich an die sich ebenfalls ändernden Geschäftsanforderungen anzupassen.
Die Basis für CSI sind Key Performance Indicators (KPIs), da ohne messbare Kennzahlen keine Verbesserung möglich ist. Typische KPI-Kategorien im Cloud-Kontext sind:
- Verfügbarkeits-KPIs – z. B. Uptime, SLA-Einhaltung
- Performance-KPIs – z. B. Response Time, IOPS
- Security-KPIs – z. B. MTTD, MTTR (Abschnitt 6.4)
- Prozess-KPIs – z. B. Anzahl erfolgreicher Changes, Incident-Lösungszeiten
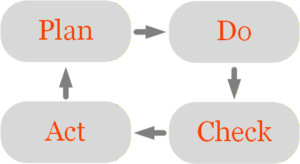
Die konzeptionelle Grundlage des CSI bildet der PDCA-Zyklus (Plan-Do-Check-Act):
- Plan – Verbesserungsziele definieren und KPIs festlegen
- Do – Maßnahmen umsetzen
- Check – Ergebnisse messen und mit KPIs vergleichen
- Act – anpassen und Zyklus neu starten
Incident Management
Wenn Sie wissen, wie auf unvorhergesehene Störungen oder Sicherheitsvorfälle reagiert werden muss, und dafür strukturierte Prozesse inklusive richtiger Priorisierung etabliert haben, dann ist Incident Management für Sie kein leeres Konzept.
ISC2-Ethik nicht vergessen: Im Notfall hat der Schutz von Menschenleben stets oberste Priorität.
Ein effektives Incident Management basiert auf einem klar definierten Ablauf, der in NIST SP 800-61 („Computer Security Incident Handling Guide„) detailliert beschrieben ist.

Die vier Phasen:
- Preparation (Vorbereitung) – Prozesse, Tools und Verantwortlichkeiten werden vorab definiert.
- Detection & Analysis (Erkennung und Analyse) – Vorfälle werden erkannt, klassifiziert und priorisiert.
- Containment, Eradication & Recovery (Eindämmung, Beseitigung und Wiederherstellung) – Der Vorfall wird eingedämmt, die Ursache beseitigt und der Normalbetrieb wiederhergestellt.
- Post-Incident Activity (Nachbereitung) – Lessons Learned, Dokumentation und Prozessverbesserung.
Problem Management
Problem Management ist direkt mit Incident Management verbunden und quasi eine Vertiefung der Post-Incident Activity. Hier wird die Antwort auf zwei Fragen gesucht: „Warum ist es zu dem Vorfall gekommen?“ und wenn die Antwort gefunden wurde: „Lässt sich der Vorfall in Zukunft vermeiden?“
Die Aktivitäten stammen direkt aus dem ITIL-Framework:
- Analyse der Vorfälle – Muster und Häufungen werden identifiziert.
- Root Cause Analysis (RCA) – die eigentlichen Ursachen werden systematisch ermittelt.
- Entwicklung von Lösungen – dauerhafte Behebung oder zumindest ein dokumentierter Workaround.
- KEDB (Known Error Database) – eine Datenbank bekannter Fehler und ihrer Workarounds erstellen/pflegen, die dem Support-Team schnelle Reaktionen ermöglicht.
Release Management
Das Release Management ist eng mit dem Change Management verbunden, konzentriert sich aber darauf, dass eine Software- oder Infrastruktur-Aktualisierung (z. B. die Implementierung neuer Features oder Bugfixes) optimal geplant, gesteuert und implementiert wird.
Der entscheidende Unterschied zwischen beiden ist: Das Change Management genehmigt und kontrolliert, ob eine Änderung durchgeführt wird. Das Release Management plant und steuert, wie sie umgesetzt wird.
Ähnlich wie im Change Management wird die technische Umsetzung durch CI/CD (Continuous Integration/Continuous Deployment) automatisiert.
Deployment Management
Das Deployment Management ist eine Form der technischen Umsetzung des Release Managements. Dabei steht die Beschreibung des technischen Rollout-Prozesses im Vordergrund. Auch hier kommt wieder CI/CD ins Spiel.
In diesem Kontext sind die drei klassischen Strategien erwähnenswert: Blue/Green Deployment, Canary Release und Rolling Deployment.
Beim Blue/Green Deployment existieren zwei identische Umgebungen parallel. Die neue Version wird in der inaktiven Umgebung bereitgestellt. Nach erfolgreicher Prüfung wird der Traffic umgeschaltet. Ein Rollback ist in diesem Fall trivial: Einfach zurückschalten. Der Nachteil: zeitweise doppelte Infrastrukturkosten.
Canary Release. Die neue Version wird zunächst nur für einen kleinen Prozentsatz der Nutzer ausgerollt. Bei Problemen wird nur dieser kleine Teil betroffen, läuft alles nach Plan, wird sie schrittweise auf alle Nutzer erweitert.
Rolling Deployment. Die neue Version wird schrittweise auf einzelne Server oder Instanzen ausgerollt, während andere noch die alte Version betreiben. Somit ist kein vollständiger Ausfall möglich, aber das Rollback ist komplexer.
Canary Release und Rolling Deployment werden in der Praxis oft kombiniert.
Configuration Management
Wenn vereinfacht gesagt das Change Management auf die Fragen „ob und wann“ beantwortet, das Release Management auf die Frage „wie“ eingeht, geht es beim Configuration Management um die Frage „was“, also mit Erfassung, Überwachung und Kontrolle aller Konfigurationen von Hard- und Softwarekomponenten.
Die bereits bekannte CMDB (Configuration Management Database, Abschnitt 5.2, Teil 2) ein zentrales Element des Configuration Managements. Sie dokumentiert den Soll- und Ist-Zustand aller Komponenten und bildet damit die Grundlage für Integrität und Compliance.
Service Level Management
Die optische Ähnlichkeit zwischen „Service Level Management“ und „Service Level Agreement“ ist kein Zufall, denn beim SLM geht es genau um die Überwachung und Einhaltung der vereinbarten Leistungsversprechen. SLM ist auch die Schnittstelle zum Continual Service Improvement (CSI). Wenn Ziele dauernd verfehlt werden, muss der Service verbessert werden.
Im Detail geht es darum, dass erwartete Leistungen und Verfügbarkeiten sowie die notwendigen Metriken und Kennzahlen genau definiert sind. Darüber hinaus sind die rechtlichen Verpflichtungen und möglichen Konsequenzen für CSPs festgelegt, sollten diese Kennzahlen unterschritten werden, typischerweise in Form von Service Credits (Gutschriften auf zukünftige Rechnungen).
Die wichtigste SLA-Kennzahlen:
- Uptime (Verfügbarkeit) – z. B. 99,99 % Betriebszeit pro Monat
- Performance (Leistung) – z.B. Netzwerkdurchsatz, Responsive, Latenz
- Support-Zeiten und Reaktionsgeschwindigkeit
- Wiederherstellungszeiten (RTO/RPO) im Störungsfall. (mehr dazu im Abschnitt 3.5)
Availability Management
Availability Management steht in direktem Zusammenhang mit dem Service Level Management und fokussiert sich ausschließlich auf die Verfügbarkeit von IT-Diensten.
Das Availability Management betrifft viele Faktoren, die im Kontext der Verfügbarkeit relevant sind. Dazu zählen beispielsweise die Verfügbarkeit geclusterter Hosts (Abschnitt 5.2), Umgebungsfaktoren und externe Einflüsse wie Stromversorgung, Kühlung, Naturkatastrophen und Cyberangriffe. Das Availability Management definiert und überwacht unteranderen die Werte RTO und RPO und stellt sicher, dass die gewählte Cloud-Architektur diese technisch einhalten kann (Abschnitt 3.5).
Die Verfügbarkeit wird typischerweise in Prozent nach dieser Formel gemessen:
Availability = (Agreed Service Time – Downtime) / Agreed Service Time × 100 %
Bei einer vereinbarten Verfügbarkeit von 720 Stunden pro Monat und einer Downtime von 0,72 Stunden ergibt sich somit:
(720 – 0,72) / 720 × 100 % = 99,9 % (Three Nines)
„Nines“-Klassifikation:
- 99,9 % (Three Nines) – ca. 8,7 Stunden Downtime pro Jahr
- 99,99 % (Four Nines) – ca. 52 Minuten Downtime pro Jahr
- 99,999 % (Five Nines) – ca. 5 Minuten Downtime pro Jahr
Capacity Management
Capacity Management ist eng mit dem Service Level Management verbunden, da ohne ausreichende IT-Ressourcen können vereinbarte Service-Levels schlicht nicht eingehalten werden.
Dabei geht es immer um die Balance zwischen Leistungsfähigkeit und Wirtschaftlichkeit:
- Zu viele Ressourcen bedeuten unnötige Kosten (Overprovisioning),
- zu wenige führen zu SLA-Verletzungen (Underprovisioning).
In der Cloud ist diese Balance besonders relevant „man zahlt für das, was man tatsächlich nutzt“.
Für ein effektives Capacity Management muss die aktuelle Auslastung der Infrastruktur (CPU, RAM, Storage, Netzwerk) sorgfältig überwacht werden (Abschnitt 5.2), inklusive Predictive Analytics, um den künftigen Bedarf auf Basis historischer Nutzungsdaten zu ermitteln.
Relevante Optimierungsmechanismen:
Auto-Scaling – Ressourcen werden automatisch nach Bedarf skaliert.
Oversubscription – mehr virtuelle Ressourcen werden zugewiesen als physisch vorhanden, in der Annahme, dass nicht alle gleichzeitig voll ausgelastet sind. Bei unerwartet hoher Last kann es zu Performance-Problemen kommen.