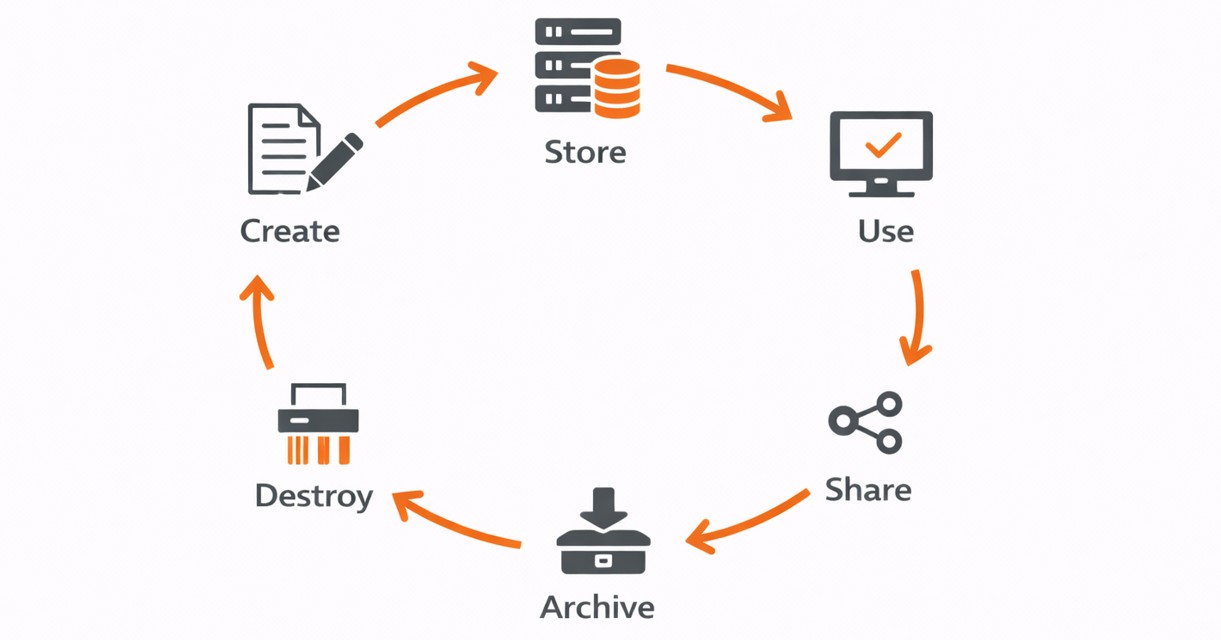
Phasen des Lebenszyklus (Data Life Cycle) von Cloud-Daten
Der Datenlebenszyklus wurde bereits in Modul 1 eingeführt. In Domain 2 steht die sicherheitstechnische Betrachtung im Mittelpunkt. Der Cloud Data Lifecycle beschreibt die Phasen, die digitale Informationen in einer Cloud-Umgebung von ihrer Entstehung bis zu ihrer endgültigen Löschung durchlaufen. Mithilfe dieses Modells können Sicherheitsmaßnahmen systematisch entlang des gesamten Lebenszyklus geplant und umgesetzt werden.
Phase 1: Create
In dieser Phase werden Daten erstmals erzeugt oder verändert, beispielsweise durch Benutzereingaben, Systemprozesse oder Anwendungscode.
Eine zentrale Sicherheitsmaßnahme ist die Datenklassifizierung, bei der Informationen entsprechend ihrer Sensitivität kategorisiert werden (z. B. öffentlich, vertraulich, geheim). Die Klassifizierung bestimmt maßgeblich die später anzuwendenden Schutzmechanismen.
Ebenso wichtig ist eine konsequente Eingabevalidierung. So können schädliche Eingaben, wie beispielsweise bei Injection-Angriffen bereits bei der Entstehung der Daten verhindert werden.
Phase 2: Store
In Phase Store werden Daten auf physischen oder virtuellen Speichersystemen abgelegt. In Cloud-Umgebungen kann es sich dabei um Objekt-, Block- oder Datenbankspeicher handeln.
Zentrale Kontrollen umfassen die Verschlüsselung im Ruhezustand sowie während der Übertragung. Zusätzlich müssen Speicherlösungen entsprechend der Datenklassifizierung ausgewählt werden.
Ein weiterer wesentlicher Aspekt sind Aufbewahrungsrichtlinien, die festlegen, wie lange Daten gespeichert werden dürfen oder müssen. Dies ist häufig regulatorischen Anforderungen geschuldet.
Phase 3: Use
Während der Nutzung werden Daten gelesen, verarbeitet oder angezeigt. In dieser Phase besteht ein erhöhtes Risiko, da die Daten oft unverschlüsselt vorliegen.
Wesentliche Maßnahmen sind daher strikte Zugriffskontrollen, idealerweise nach dem Least-Privilege-Prinzip. Auch umfassendes Logging und Monitoring sind wichtig, um jede Nutzung nachvollziehbar zu machen.
Techniken wie Data Masking oder rollenbasierte Sichten reduzieren das Risiko der Offenlegung sensibler Informationen.
Information Rights Management (IRM) und Digital Rights Management (DRM) werden insbesondere in den Phasen „Use“ und „Share“ eingesetzt. Während die Verschlüsselung primär die Speicherung und Übertragung schützt, kontrolliert das Information Rights Management (IRM) die konkrete Nutzung der Daten, beispielsweise das Drucken, Kopieren oder Weiterleiten, selbst nachdem diese die ursprüngliche Schutzumgebung verlassen haben.
Phase 4: Share
Beim Teilen von Daten verlassen Informationen häufig die ursprüngliche, sichere Umgebung. An dieser Stelle sind eine starke Authentifizierung und Autorisierung, eine verschlüsselte Übertragung (z. B. TLS-gesicherte Verbindungen) sowie klar definierte Data Usage Agreements von entscheidender Bedeutung.
Phase 5: Archive
Archivierte Daten werden aus verschiedenen Gründen langfristig aufbewahrt, meist aus Compliance- oder Nachweisgründen, manchmal aber auch aus historischen Gründen. Typische Maßnahmen umfassen die Nutzung kosteneffizienter Archivspeicher und regelmäßige Integritätsprüfungen, um Manipulationen auszuschließen.
Ein häufig unterschätzter Faktor ist das Schlüsselmanagement: Die Lebensdauer kryptographischer Schlüssel muss mindestens der Aufbewahrungsdauer der Daten entsprechen. Archivierte Daten werden häufig in kosteneffizienten Langzeitspeichern abgelegt, etwa in Cold-Storage-Systemen oder WORM-konformen (Write Once Read Many) Speichermedien. Auch wenn Cloud-Kunden keinen direkten Zugriff auf physische Medien haben, bleiben Aspekte wie Standort, Unveränderbarkeit und Integrität wichtig.
Phase 6: Destroy
In der letzten Phase werden Daten dauerhaft entfernt, sobald sie nicht mehr benötigt werden oder die gesetzlichen Aufbewahrungsfristen abgelaufen sind.
In Cloud-Umgebungen besteht in der Regel keine direkte Kontrolle über die zugrunde liegende Hardware. Klassische Verfahren wie das mehrfache Überschreiben physischer Datenträger sind für Kunden daher meist nicht praktikabel. Als besonders effektive Methode gilt stattdessen Crypto Shredding: Dabei wird der zugehörige Verschlüsselungsschlüssel endgültig vernichtet. In der Praxis bedeutet die Vernichtung eines Verschlüsselungsschlüssels dessen irreversible Entfernung aus dem Schlüsselmanagementsystem.
Rollen im Cloud Data Lifecycle
Unabhängig von der jeweiligen Phase ist zwischen den Rollen des Dateneigentümers (Data Owner) und des Datenverwalters (Data Custodian) zu unterscheiden.
- Der Data Owner trägt die fachliche Verantwortung für die Daten. Er entscheidet über Klassifizierung, Schutzbedarf, Zugriffsvorgaben und Aufbewahrungsfristen. Diese Rolle liegt typischerweise bei einer Fachabteilung oder einem Geschäftsverantwortlichen.
- Der Data Custodian ist hingegen für die technische Umsetzung der Schutzmaßnahmen verantwortlich. Dazu zählen unter anderem Verschlüsselung, Zugriffskontrollen, Backup-Strategien und Löschverfahren. In Cloud-Umgebungen kann diese Rolle je nach Servicemodell teilweise beim Cloud-Service-Provider liegen.
Streuung der Daten (Data Dispersion)
Als Datendispersion wird die Aufteilung von Daten in mehrere Fragmente bezeichnet, die über unterschiedliche Speicherorte oder Systeme verteilt werden. Das Ziel besteht darin, die Verfügbarkeit, Ausfallsicherheit und teilweise auch die Sicherheit zu erhöhen.
In vielen Informationsquellen wird dieses Konzept mit einem Puzzle verglichen. Das vollständige Datenset wird in einzelne Segmente zerlegt. Erst durch die Zusammenführung einer definierten Anzahl dieser Fragmente kann der ursprüngliche Inhalt rekonstruiert werden.
Technisches Prinzip
Wenn Daten in Fragmente aufgeteilt und verteilt gespeichert werden, fügt Erasure Coding zusätzliche Redundanzfragmente (sogenannte Paritätsdaten) hinzu. Diese werden durch mathematische Berechnungen aus den Originalfragmenten erzeugt. Gehen durch einen Festplattenausfall ein oder mehrere Fragmente verloren, können die fehlenden Daten aus den verbleibenden Fragmenten und den Paritätsdaten rechnerisch wiederhergestellt werden.
Das Verfahren ähnelt konzeptionell RAID-Mechanismen, geht jedoch darüber hinaus: die Fragmente sind häufig geografisch verteilt und werden über mehrere Rechenzentren hinweg gespeichert.
Vorteile und Risiken der Datendispersion
Der größte Vorteil der Datendispersion besteht darin, dass sie Systeme robuster gegenüber Ausfällen macht. Da die Daten nicht an einem einzigen Ort vollständig gespeichert sind, führt der Ausfall eines Speichersystems oder sogar eines ganzen Rechenzentrums nicht zwangsläufig zum Datenverlust. Solange eine ausreichende Anzahl von Fragmenten verfügbar ist, kann das ursprüngliche Datenset rekonstruiert werden.
Gleichzeitig bringt dieses Verfahren jedoch auch neue Herausforderungen mit sich. So kann die Rekonstruktion fragmentierter Daten zusätzliche Latenz verursachen, insbesondere wenn die Fragmente geografisch verteilt gespeichert sind. Hinzu kommt, dass die Architektur komplexer wird, da Metadaten, Integrität und gegebenenfalls kryptographische Schlüssel konsistent verwaltet werden müssen.
Ein weiterer kritischer Aspekt betrifft regulatorische Anforderungen. Wenn Fragmente über verschiedene geografische Regionen oder Rechtsräume verteilt werden, kann dies mit Vorgaben zur Datenlokalisierung kollidieren.
Datenströme (Data Flows)
Ein Data Flow beschreibt die Bewegung von Daten zwischen Systemen, Anwendungen und Nutzern. In der Vergangenheit, als Anwendungen noch monolithisch aufgebaut waren, war dieser Weg vergleichsweise überschaubar. Moderne Cloud-Architekturen bestehen jedoch aus vielen unabhängigen, miteinander kommunizierenden Komponenten, den sogenannten Microservices, APIs oder serverlosen Funktionen. Das Ergebnis ist ein hochflexibles, leistungsfähiges System.
In der Cloud ist es schwieriger zu erkennen, wo sich Daten zu einem bestimmten Zeitpunkt tatsächlich befinden, welche Wege sie nehmen, welche Schnittstellen bzw. Protokolle dabei genutzt werden und welche Ports offen sind. Diese fehlende Transparenz ist nicht nur ein organisatorisches Problem, sondern auch ein Sicherheitsrisiko, denn wer den Datenfluss versteht, kontrolliert die Datensicherheit.
Zur Analyse und Dokumentation werden Data-Flow-Diagramme (DFDs) eingesetzt. Sie visualisieren, welche Systeme miteinander kommunizieren, in welche Richtung Daten fließen und an welchen Stellen sicherheitsrelevante Kontrollen wie Verschlüsselung oder Authentifizierung greifen. Gerade im Hinblick auf Compliance-Anforderungen, wie sie die DSGVO stellt, ist Klarheit über Datenbewegungen enorm wichtig.