Im letzten Abschnitt des fünften Moduls geht es darum, mit welchen Mitteln Bedrohungen in Echtzeit erkannt und analysiert werden. Und wenn man tiefer blickt, geht es um Logs, sehr viele Logs.
Security Operations Center (SOC)
Mittlerweile wird der Begriff SOC so inflationär benutzt, dass er je nach Quelle ganz unterschiedlich ausgelegt wird. Auch die Existenz der Prüfberichte namens SOC 1, SOC 2 und SOC 3 vereinfacht die Situation gerade nicht. Eins ist schon mal klar: SOC ist keine Software.
Wenn wir IBM fragen würden, dann ist SOC „ein internes oder ausgelagertes Team von IT-Sicherheitsexperten, das die gesamte IT-Infrastruktur eines Unternehmens rund um die Uhr überwacht.“
Aber auch Microsoft hat eine Ahnung von IT und definiert SOC so: „Ein SOC ist eine zentrale Funktion oder ein zentrales Team, das für die Verbesserung der Cybersicherheitsposition und die Verhinderung, Erkennung und Reaktion auf Bedrohungen einer Organisation verantwortlich ist.“
Somit ist klar: Das SOC ist ein Team, ein Team, das sich mit der operativen IT-Sicherheit beschäftigt, alle sicherheitsrelevanten Ereignisse 24/7 überwacht, sammelt und analysiert und auf Basis der Ergebnisse entsprechende Maßnahmen ergreift.
Moderne SOCs agieren dabei nicht nur reaktiv, sondern zunehmend auch proaktiv. Mithilfe von Threat Hunting suchen sie aktiv nach Bedrohungen, bevor Alarme ausgelöst werden und es zu Schäden kommt.
SOC aus technischer Sicht
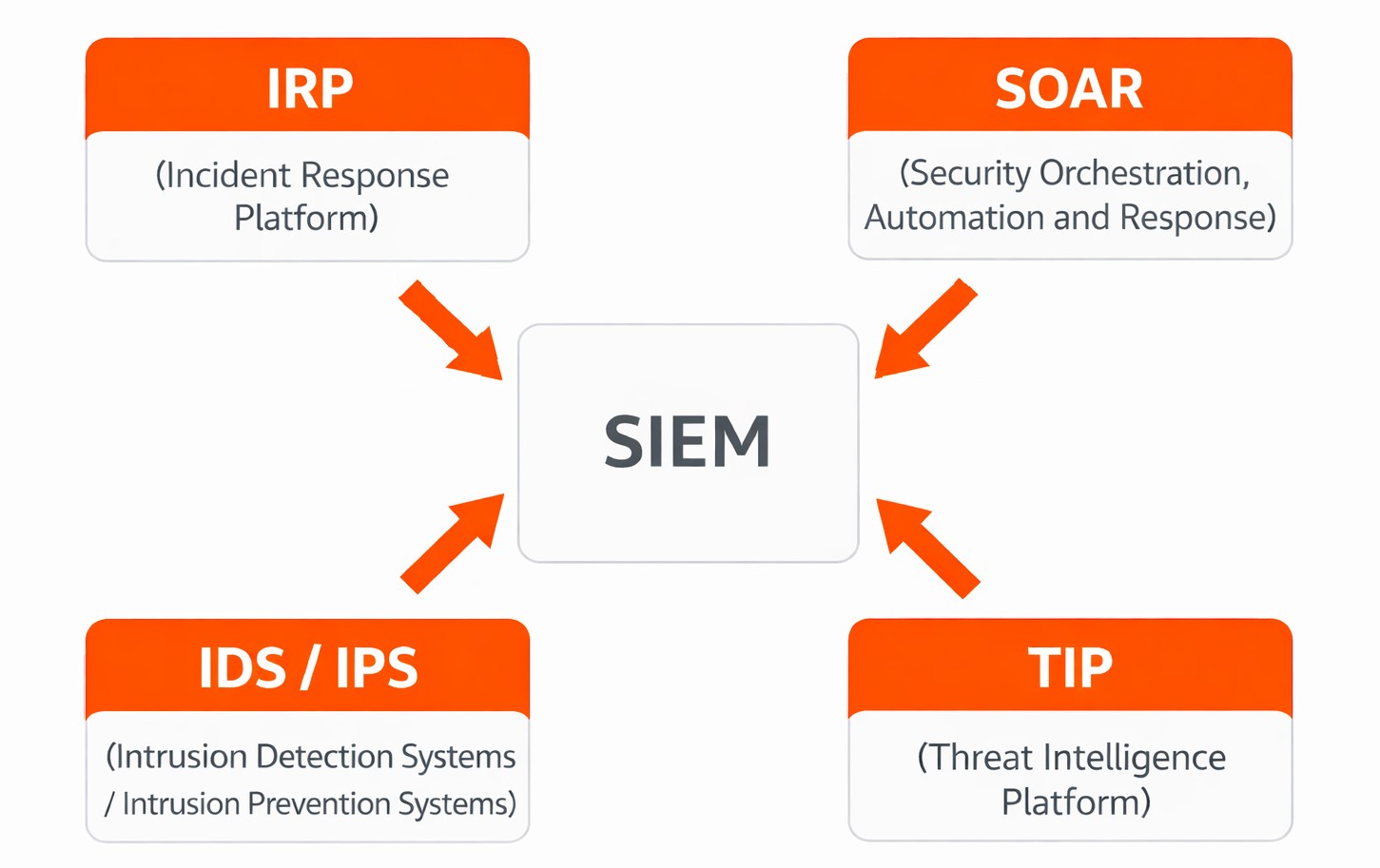
Aus technischer Sicht ist SOC eine breite Palette an Tools, die seine technische Grundlage bilden. Die Kernkomponenten sind:
SIEM (Security Information and Event Management) ist das Herzstück des SOCs. Es sammelt und korreliert sicherheitsrelevante Ereignisse aus der gesamten Infrastruktur und erkennt verdächtige Anomalien.
IRP (Incident Response Platform) ist eine spezialisierte Plattform zur strukturierten Bearbeitung, Dokumentation und Nachverfolgung von Sicherheitsvorfällen.
Threat Intelligence Platform (TIP) die reichert SIEM und Incident Response mit externen Bedrohungsinformationen an. Dazu gehören IOCs (Indicators of Compromise, z. B. bekannte Malware-Hashes oder verdächtige IP-Adressen) sowie TTPs (Tactics, Techniques, Procedures, also Angriffsmuster bekannter Bedrohungsakteure).
SOAR (Security Orchestration, Automation and Response) automatisiert wiederkehrende SOC-Aufgaben und orchestriert die Reaktion auf Vorfälle.
IDS/IPS liefern dem SOC Erkennungssignale aus dem Netzwerk, wurden bereits in Abschnitt 5.2 behandelt.
SOC = Technologie + Menschen + Prozesse
Eine wichtige Ergänzung zu allem bisher Gesagten: Ein SOC ist mehr als nur eine Sammlung von Tools. Es basiert auf drei gleichwertigen Säulen. Fehlt eine davon, funktioniert das SOC nicht.
- Technologie: SIEM, IRP, SOAR, TIP, IDS/IPS (es kann natürlich auch mehr sein)
- Menschen: Analysten mit definierten Rollen und Fachkenntnissen. Die SOC-Analysten werden typischerweise in drei Erfahrungsstufen eingeteilt: Level 1, 2 und 3.
- Prozesse: klar definierte Abläufe für jeden Anwendungsfall.
Typische SOC-Aufgaben
Hier ist eine grobe Auflistung möglicher Aufgaben ohne Anspruch auf Vollständigkeit.
- Monitoring auf Verbreitung von Schadsoftware
- Überwachung von Servern und Active Directory
- Erkennung von Datenlecks (z. B. über DLP)
- Monitoring privilegierter Benutzer
- Überwachung von IPS-Ereignissen
- Compliance-Kontrolle
- Erkennung anomaler Aktivitäten auf kritischen Systemen
- Vulnerability Management, Kontrolle der Schwachstellenbehebung
Incident-Priorisierung im SOC
Nicht jedes Ereignis im Bereich der IT-Sicherheit erfordert dieselbe Reaktionsgeschwindigkeit und Bearbeitungszeit. Die eingehenden Incidents werden zunächst validiert, bewertet und priorisiert (die sogenannte Triage). Oft erfolgt die Einstufung auf Basis des Prioritätsscores (z. B. 0–10).
Die konkrete Gestaltung dieser Schwellenwerte und Reaktionszeiten ist organisationsspezifisch und nicht standardisiert.
Intelligente Überwachung von Sicherheitskontrollen
Wer überwacht die Überwacher eigentlich? Die Antwort ist einfach: diejenigen, die das betreiben. Sicherheitskritische Komponenten bedürfen ebenfalls eines kontinuierlichen Monitorings.
Die Relevante Überwachungsaspekte sind:
Aktualität. Werden die Regeln und Signaturen regelmäßig aktualisiert? Da ohne regelmäßigen Updates werden neue Angriffsmuster nicht erkannt. Sind die Firmware noch aktuell?
Performance und Kapazität. Sind die Hardware-Ressourcen noch ausreichend? Oder platzt das System bereits aus allen Nähten? Die Log-Speicher neigen oft dazu, vollzulaufen.
Zugriffskontrolle. Werden die administrativen Zugriffe auf kritische Systeme regelmäßig verifiziert?
Log Management und Analyse
Logs sind in der IT-Security einfach alles, unser A und O. Sie bilden die Grundlage für die Erkennung, Analyse und weitere Aufklärung von Sicherheitsvorfällen.
Alle IT-Systeme produzieren Logs, einige mehr, andere weniger. Bei einigen lassen sich die Logs konfigurieren, bei anderen sind sie vordefiniert. Dank Logs werden sämtliche Aktivitäten in Systemen, Netzwerken und Anwendungen akribisch erfasst und gespeichert.
Log Management beschäftigt sich mit der strukturierten Erfassung, zentralen Speicherung und Verwaltung von Protokolldaten aus verschiedenen Quellen, mit Fokus auf sicherheitsrelevante Ereignisse.
Log Analyse geht noch einen Schritt weiter und bezieht sich auf die Auswertung dieser Daten.
Das primäre Werkzeug für die Log-Analyse im Security-Kontext ist ein SIEM-System, z.B. Splunk (Was ist SIEM), Microsoft Sentinel oder IBM QRadar.
Auf SIEM werden die Logs aus vielen Quellen in gigantische Mengen gesammelt, normalisiert und anschließend korreliert, um bestimmte Ausfälligkeiten zu erkennen. Die Korrelation von Ereignisse ist genau die intelligente Analyse.
Die Normalisierung ist ebenfalls ein wichtiger Schritt, da die Logs unterschiedliche Formate haben und müssen in ein einheitliches Format überführt werden, die Felder werden standardisiert.
Incident Management
Aus Security-Sicht wird als Incident jedes ungeplante Ereignis bezeichnet, das einen der drei Aspekte der CIA-Triade (Vertraulichkeit, Integrität, Verfügbarkeit) beeinträchtigt.
Incident Management hat drei Kernziele: den durch den Incident entstandenen Schaden minimieren, die Ursache beseitigen und daraus lernen. Die Phasen des Incident Response wurden bereits in Abschnitt 5.3 (NIST SP 800-61) ausführlich behandelt.
Die Priorität eines Incidents wird durch zwei Faktoren beeinflusst: Impact (Auswirkung) und Urgency (Dringlichkeit).
- Impact : Wie groß ist der Schaden? Wie viele Systeme oder Benutzer sind betroffen?
- Urgency (Dringlichkeit): Wie schnell muss reagiert werden, um einen Schaden zu vermeiden, bevor es eskaliert?
Das zugrunde liegende Prinzip lautet: Priority = Impact × Urgency
Incident Response Plan (IRP). Der IRP existiert, bevor ein Incident passiert. Er definiert Prozesse, Verantwortlichkeiten, Kommunikationswege und technische Abläufe für den Ernstfall. Ein IRP muss regelmäßig geübt und immer aktuell gehalten werden.
Incident Response Team (IRT). Das IRT Team ist für die Umsetzung/Ausführung des IRPs zuständig. Wenn das Security Operations Center (SOC) einen Incident erkennt und alarmiert, reagiert das Incident Response Team (IRT) darauf. Das IRT ist ein multidisziplinäres Team, das nicht nur aus IT-Sicherheitsexperten besteht. Auch die Rechtsabteilung und das PR-Team sind oft dabei, da ein Sicherheitsvorfall im schlimmsten Fall rechtliche Konsequenzen und Reputationsschäden nach sich ziehen kann.
Die koordinierende Rolle innerhalb des IRT übernimmt der Incident Response Coordinator. Er trifft keine technischen Entscheidungen, ist aber die zentrale Kommunikationsschnittstelle zwischen allen Beteiligten: IT, Management, Legal, PR usw.
Vulnerability Assessments / Schwachstellenanalysen
Ein Vulnerability Assessment ist ein systematischer Prozess zur Identifikation, Bewertung und Priorisierung von Sicherheitslücken. Es handelt sich dabei um eine proaktive und regelmäßige Maßnahme, um Schwachstellen zu finden, bevor ein Angreifer sie ausnutzen kann.
Automatisierte Scanner wie OpenVAS, Nessus oder Qualys finden potenzielle Schwachstellen. Der Begriff „potenziell” ist hier wichtig, da nicht jeder Fund eine echte Schwachstelle ist (es kann sogenannte False Positives sein). Das eigentliche Assessment bewertet und priorisiert diese Ergebnisse.
Die Suche nach Schwachstellen erfolgt über drei Wege:
Automatisierte Scans durchsuchen Systeme nach fehlenden Patches, unsicheren Konfigurationen, veralteten Versionen und bekannten Schwachstellen (CVEs). Dabei unterscheidet man zwischen:
- Credentialed (oder authenticated) Scan: Der Scanner meldet sich mit einem System-Account an und liefert präzisere Ergebnisse mit weniger False Positives.
- Uncredentialed (oder unauthenticated) Scan: Ohne Zugangsdaten wird die Perspektive eines externen Angreifers simuliert.
Manuelle Prüfungen. Diese werden von Sicherheitsanalysten im Rahmen von Penetrationstests oder Audits durchgeführt, um komplexe Sicherheitslücken zu erkennen, die Scanner möglicherweise übersehen.
Kombinierter Ansatz. Automatisierte Scans bieten Breite, manuelle Prüfungen Tiefe – in der Praxis der empfohlene Standard.