Die Datenklassifizierung ist ein entscheidender Bestandteil einer Cloud-Sicherheitsstrategie. In diesem Kontext erinnern wir uns an die Create-Phase (erste Phase) des Cloud Security Data Lifecycles. In dieser Phase sollte bereits festgelegt werden, welche Sensitivität die Daten besitzen und welche Schutzmaßnahmen erforderlich sind.
Richtlinien zur Datenklassifizierung
Richtlinien zur Datenklassifizierung verfolgen im Wesentlichen zwei Ziele: Identifikation und Kategorisierung von Daten.
Zunächst wird ermittelt, welche Arten von Daten innerhalb eines Unternehmens verarbeitet werden. Im nächsten Schritt werden diese Daten anhand verschiedener Attribute klassifiziert, beispielsweise nach Sensitivität, Datenverantwortlichen, gesetzlichen Anforderungen oder Speicherort.
Auf Grundlage dieser Klassifizierung werden anschließend konkrete Schutzanforderungen für jede Datenkategorie festgelegt. Dazu zählen beispielsweise Vorgaben zur Verschlüsselung, Zugriffskontrollen, Aufbewahrungsfristen und die Regelung der Weitergabe von Daten.
Die typische Klassifizierungsstufe und Schutzmaßnahmen sind:
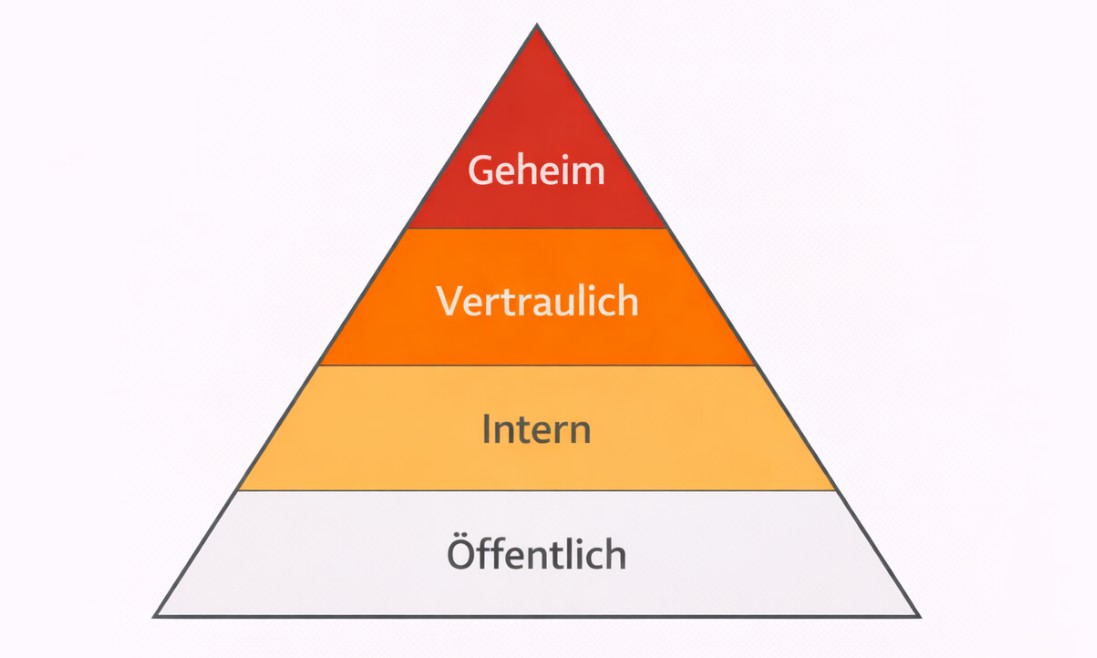
Öffentlich – frei zugängliche Daten (z. B. Marketingmaterial, öffentliche Webseiten). Es sind keine besonderen Schutzmaßnahmen erforderlich.
Intern – Daten, die nur innerhalb des Unternehmens zugänglich sein sollen (z. B. interne Richtlinien, Projektdokumente). Schutzmaßnahmen: Zugriffskontrolle, Authentifizierung sowie Verschlüsselung im Transit.
Vertraulich – sensible Daten mit erhöhtem Schutzbedarf (z. B. Kundendaten, Finanzdaten, personenbezogene Daten). Eine Offenlegung könnte dem Unternehmen schaden. Schutzmaßnahmen: starke Zugriffskontrollen, Verschlüsselung im Ruhezustand und im Transit sowie Protokollierung und Überwachung.
Geheim / Streng vertraulich – höchste Schutzstufe für besonders kritische Informationen. Ein unbefugter Zugriff auf solche Information könnte erhebliche rechtliche, finanzielle oder rufschädigende Folgen haben. Schutzmaßnahmen: Multi-Faktor-Authentifizierung, starke Verschlüsselung, strenges Schlüsselmanagement usw.
Data Mapping
Als Data Mapping (Datenzuordnung) wird die systematische Erfassung und Abbildung von Datenbeständen in einer Organisation bezeichnet, um eine vollständige Übersicht über alle Systeme und Speicherorte zu erhalten.
Aus organisatorischer Sicht ist es der Prozess, bei dem festgestellt wird, wo Daten gespeichert sind, welche Art von Daten dort liegen und welche Klassifizierungsstufe oder Sensitivität diesen Daten zugeordnet wird. All dies verfolgt das Ziel, Risiken zu bewerten und geeignete Sicherheitsmaßnahmen anzuwenden.
Der Prozess der Datenzuordnung verläuft in dieser Reihenfolge:
- Identifikation der Systeme – alle physischen und logischen Systeme, die Daten speichern oder verarbeiten, werden erfasst.
- Erstellung einer Dateninventur – hier erfolgt die Zuordnung von Speicherorten zu den vorhandenen Datentypen.
- Klassifizierung – die erfassten Daten werden bewertet und einer Klassifizierungsstufe (z. B. öffentlich, intern, vertraulich) zugeordnet.
- Labels und Metadaten – Abschließend werden Tags und Metadaten hinzugefügt, um den Schutzbedarf maschinenlesbar zu machen und automatisierte Schutzmaßnahmen anzuwenden.
Data Labeling
Data Labeling (Datenkennzeichnung) ist die praktische Umsetzung der letzten Schritte, bei denen Labels und Metadaten hinzugefügt werden.
Das Labeling kann in zwei Hauptkategorien unterteilt werden:
Physisches Labeling – dazu zählen die klassischen Markierungen auf physischen Geräten, zum Beispiel Barcode-Aufkleber oder Etiketten. In der heutigen digitalen Welt spielt physisches Labeling eine untergeordnete Rolle, bleibt aber in regulierten Branchen und bei der Hardware-Inventarisierung relevant.
Digitales Labeling – hierbei geht es um verschiedene Arten der Markierung, die oft vollständig automatisiert abläuft. Mögliche Beispiele sind Metadaten, Dateinamen oder -präfixe, Header oder Footer in Dokumenten sowie digitale Wasserzeichen.