Lebenszyklus von Daten in der Cloud
Die Sicherheitsmaßnahmen müssen sich nicht nur in der Cloud, sondern überall am Lebenszyklus der Daten orientieren. Von der Erstellung über die Speicherung und Nutzung bis zur finalen Löschung ändern sich die Bedrohungen und die erforderlichen Kontrollen. Gleichzeitig entwickelt sich die Bedrohungslandschaft ständig weiter: Neue Angriffsvektoren entstehen, Angreifer werden raffinierter und Cloud-spezifische Schwachstellen werden ausgenutzt.
Cloud Data Lifecycle
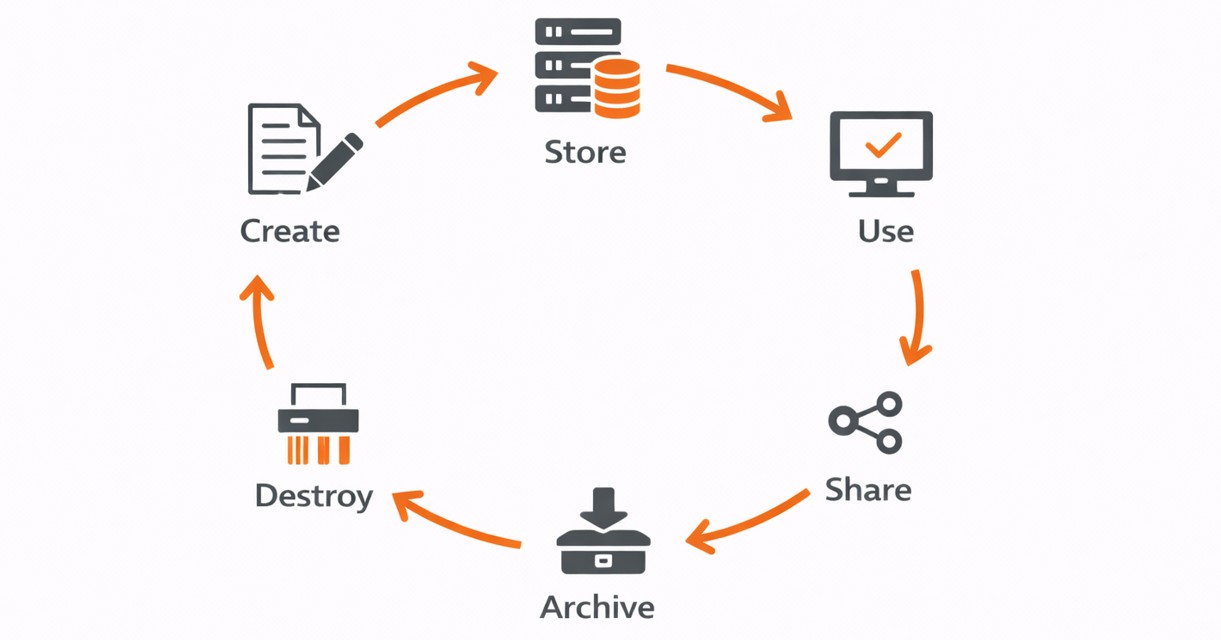
Daten durchlaufen sechs distinkte Phasen: Create, Store, Use, Share, Archive, Destroy. Jede Phase erfordert spezifische Sicherheitskontrollen.
Create: Sichere Erstellung
Die Datenklassifizierung muss bei der Erstellung erfolgen, nicht nachträglich. Ein neu erstelltes Dokument, eine Datenbanktransaktion oder eine Log-Datei müssen beispielsweise sofort mit dem richtigen Sensitivitätslabel versehen werden. Diese Labels bestimmen alle nachfolgenden Sicherheitsmaßnahmen: Dazu gehören die Verschlüsselungsstärke, Zugriffskontrollen und Aufbewahrungsfristen.
In dieser Phase ist die Input Validation kritisch. Anwendungen müssen Benutzereingaben validieren und sanitisieren, bevor Daten dauerhaft gespeichert werden. SQL-Injection, Cross-Site-Scripting und andere Injection-Angriffe nutzen oft fehlende oder mangelhafte Input-Validation aus.
Store: Sichere Speicherung
Die Verschlüsselung im Ruhezustand ist Pflicht und keine Option. Bei der Wahl zwischen Provider-Managed Keys und Customer-Managed Keys liegt die Entscheidung primär beim Kunden. Ersteres ist bequemer, Letzteres bietet stärkere Kontrolle.
Zugriffskontrollen auf Speicherebene müssen dem Least-Privilege-Prinzip folgen. Datenbankzugriffe sollten auf die minimal notwendigen Tabellen und Spalten beschränkt sein.
Use: Kontrollierte Verarbeitung
Besonders kritisch sind Daten im sogenannten Data-in-Use-Zustand, da sie hier nicht ausschließlich durch kryptographische Verfahren geschützt werden können. Um die Daten verarbeitet zu können, müssen sie zuerst entschlüsselt werden, wodurch sie potenziell angreifbar werden.
Die Datenmaskierung reduziert das Risiko unbeabsichtigter Einsicht, indem sie nur Teilinformationen anzeigt. Ein wirksamer Schutz von Daten während der Verarbeitung erfordert vor allem restriktive Zugriffsmodelle. Jeder Zugriff auf sensible Daten muss protokolliert werden. Bei Bedarf muss geantwortet werden können, wer wann auf welche Daten zugegriffen hat.
Share: Sichere Weitergabe
Werden Daten die ursprüngliche Organisation verlassen, müssen sowohl die Übertragung als auch die anschließende Nutzung abgesichert werden. Während des Transports ist eine starke Verschlüsselung obligatorisch, beispielsweise durch TLS für Web-Traffic oder IPsec für Site-to-Site-VPNs. Für besonders schützenswerte Informationen kann eine zusätzliche Verschlüsselung auf Anwendungsebene als zweite Verteidigungslinie (z.B. verschlüsselte E-Mail) dienen.
Technologien wie Digital Rights Management (DRM) und Information Rights Management (IRM) können bestimmte Nutzungsbeschränkungen technisch durchsetzen, etwa das Weiterleiten oder Drucken vertraulicher Dokumente.
Archive: Langzeitspeicherung
Auf archivierte Daten wird selten zugegriffen, sie müssen aber oft aus Compliance-Gründen jahrelang verfügbar bleiben. Lösungen wie „Cold Storage“, beispielsweise AWS-Glacier oder Azure Archive Storage können die Kosten niedrig halten, indem sie die längere Zugriffszeit gegen niedrigere Speicherpreise kompensieren.
In diesem Fall wird das Schlüsselmanagement kritisch. Verschlüsselungsschlüssel müssen mindestens so lange verfügbar sein wie die archivierten Daten.
Destroy: Sichere Löschung
Crypto Shredding ist die einzige zuverlässige Löschmethode für die Cloud. Dabei wird der Verschlüsselungsschlüssel vernichtet, wodurch die verschlüsselten Daten wertlos werden.
Konfigurierte Retention Policies können eine automatische Löschung gewährleisten. Daten, die nach Ablauf der gesetzlichen Aufbewahrungsfrist nicht mehr benötigt werden, sollten unteranderem aus Compliance -Sicht automatisch gelöscht werden.
Business Continuity und Disaster Recovery
Business Continuity zielt darauf ab, kritische Geschäftsprozesse auch bei Störungen aufrechtzuerhalten. Neben Vertraulichkeit und Integrität ist Verfügbarkeit somit eine dritte Säule der Informationssicherheit.
Business Continuity und Disaster Recovery sind eng miteinander verbunden. Beide werden aktiv, wenn eine Störung oder Katastrophe auftritt – sei es eine physische Katastrophe (z. B. Brand, Überschwemmung, Erdbeben oder Stromausfall) oder ein Cyberangriff (z. B. Ransomware, Denial-of-Service oder Insider-Angriff).
Trotz ihres gemeinsamen Ziels, die Auswirkungen solcher Ereignisse auf Betrieb, Verfügbarkeit und Sicherheit zu minimieren, unterscheiden sich Business Continuity und Disaster Recovery in ihrem Fokus und zeitlichen Ansatz.
Business Continuity Plan (BCP)
Ein Business-Continuity-Plan legt fest, wie essenzielle Geschäftsprozesse während und unmittelbar nach einem Vorfall aufrechterhalten werden können. Das Ziel besteht darin, den Kernbetrieb trotz Störung aufrechtzuerhalten, bis eine vollständige Wiederherstellung möglich ist.
Wenn beispielsweise eine Überschwemmung das primäre Rechenzentrum beschädigt, können Kundentransaktionen durch die Umleitung auf cloudbasierte Systeme oder alternative Rechenzentren trotzdem verarbeitet werden.
Disaster Recovery Plan (DRP)
Ein Disaster-Recovery-Plan beschreibt die Wiederherstellung aller Systeme und Dienste nach einem Vorfall, um den Normalbetrieb wiederherzustellen. Dies kann die folgenden Schritte beinhalten: Neuaufbau von Servern mithilfe von Infrastructure-as-Code-Templates, Wiederherstellung von Daten aus Backups, Validierung und Test der vollständigen Systemintegrität.
Business Impact Analysis (BIA)
Im Rahmen der Business-Impact-Analyse werden zunächst alle geschäftskritischen Assets identifiziert. Dazu zählen nicht nur Daten, Anwendungen und Infrastrukturkomponenten, sondern auch zentrale Geschäftsprozesse sowie das für ihren Betrieb erforderliche Personal.
Anschließend wird analysiert, welche finanziellen, betrieblichen und regulatorischen Konsequenzen ein Ausfall dieser Ressourcen hätte. Neben direkten Umsatzverlusten können auch Reputationsschäden, Vertragsverletzungen oder rechtliche Folgen entstehen.
Auf Basis dieser Bewertung werden weitere Schutz- und Wiederherstellungsmaßnahmen priorisiert. Organisationen müssen festlegen, welche Systeme im Störungsfall zuerst wiederhergestellt werden müssen, um den Geschäftsbetrieb aufrechtzuerhalten.
Dabei dienen folgende Kennzahlen als zentrale Entscheidungsgrundlage:
- Recovery Time Objective (RTO)
- Recovery Point Objective (RPO)
Kosten-Nutzen-Analyse (Cost-Benefit Analysis)
Die Kosten-Nutzen-Analyse ergänzt die Business-Impact-Analyse, indem sie bewertet, ob geplante Sicherheitsmaßnahmen oder Cloud-Architekturen in einem angemessenen Verhältnis zu ihrem Nutzen stehen. Eine solche Analyse hilft dabei, fundierte Entscheidungen über Investitionen in die Cloud-Sicherheit zu treffen.
Es ist wichtig, auch die potenziellen Nachteile zu berücksichtigen. Dazu zählen beispielsweise der Verlust der Kontrolle über die zugrunde liegende Infrastruktur (insbesondere bei Public Clouds), das Risiko von Dienstunterbrechungen sowie der Aufwand für Schulung, Implementierung und Verwaltung.
Return on Investment
Der Return on Investment (ROI) ist eine Kennzahl, mit der sich der wirtschaftliche Nutzen von Sicherheitsinvestitionen im Verhältnis zu ihren Kosten bewerten lässt. Da Sicherheitsmaßnahmen keine direkten Gewinne generieren, zeigt sich ihr Wert vor allem in der Reduzierung von Risiken und der Vermeidung potenzieller Schäden.
Investitionen können sich beispielsweise durch effizientere Betriebsabläufe, geringere Ausfallzeiten oder die Vermeidung kostspieliger Sicherheitsvorfälle auszahlen.
Die Formel lautet: ROI = (reduzierte Risiken oder vermiedene Schäden – Investitionskosten) ÷ Investitionskosten.
Funktionale Sicherheitsanforderungen
Auf Grundlage der Analyse der geschäftlichen Auswirkungen muss definiert werden, welche technischen und funktionalen Eigenschaften Cloud-Systeme erfüllen müssen, damit sie sicher, flexibel und langfristig betreibbar sind. Dabei spielen insbesondere die folgenden Aspekte eine zentrale Rolle:
- Portabilität
- Interoperabilität
- Vermeidung von Vendor Lock-in.
Die nachfolgenden Aspekte wurden bereits im Abschnitt „Gemeinsame Überlegungen beim Cloud-Design“ erläutert. Aufgrund ihrer grundlegenden Bedeutung werden sie hier noch einmal zusammengefasst.
Portabilität
Als Portabilität wird die Fähigkeit eines Systems oder einer Anwendung bezeichnet, mit minimalem Aufwand zwischen verschiedenen Umgebungen zu wechseln, beispielsweise von On-Premises in die Cloud oder zwischen unterschiedlichen Cloud-Anbietern.
Um diese Herausforderungen zu bewältigen, setzen Unternehmen auf containerbasierte Plattformen wie Kubernetes, die von allen großen Cloud-Providern unterstützt werden, sowie auf Cloud-agnostische Technologien wie z.B. Terraform.
Interoperabilität
Als Interoperabilität wird die Fähigkeit von Systemen und Anwendungen bezeichnet, über verschiedene Plattformen und Anbieter hinweg nahtlos miteinander zu kommunizieren und Daten auszutauschen.
In hybriden und Multi-Cloud-Umgebungen stellt die Interoperabilität eine zentrale Herausforderung dar: Unterschiedliche Sicherheitsstandards, proprietäre Schnittstellen sowie abweichende Identitäts- und Verschlüsselungsmechanismen der Cloud-Service-Provider erschweren den sicheren Austausch von Daten und Diensten.
Vendor Lock-in
Als Vendor Lock-in wird eine Situation bezeichnet, in der ein Unternehmen von einem bestimmten Cloud-Anbieter abhängig ist, weil seine Anwendungen oder Systeme auf spezifischen, proprietären Diensten dieses Anbieters basieren.
Vendor Lock-in ist ein wesentliches strategisches Risiko in Cloud-Umgebungen. Es entstehen finanzielle Abhängigkeiten, wenn Preisänderungen eines Anbieters nicht ohne Weiteres durch einen Wechsel kompensiert werden können. Hinzu kommen technische Risiken, da Migrationen zwischen Plattformen häufig mit erheblichem Aufwand verbunden sind oder aufgrund proprietärer Technologien nur eingeschränkt möglich sind. Auch vertragliche Rahmenbedingungen können die Flexibilität einschränken.
Um diese Risiken zu reduzieren, empfiehlt sich der Einsatz plattformunabhängiger Technologien.
Ein Vendor Lock-in ist nicht immer vermeidbar, denn manchmal ist die Nutzung proprietärer Dienste wirtschaftlich sinnvoll. Wichtig ist, die damit verbundenen Risiken bewusst in die Gesamtstrategie zu integrieren.